使用whisper.cpp听译字幕

输出16bit原始音频
ffmpeg -i audio.mp4 -ar 16000 -ac 1 -c:a pcm_s16le audio_output.wav
clone & cd
git clone https://github.com/ggerganov/whisper.cpp.git
cd whisper.cpp
ggml模型下载
bash ./models/download-ggml-model.sh {model}
可用模型
# 查看可用模型
bash ./models/download-ggml-model.sh

带en的model仅支持英文
使用
make
$ ./main -h
usage: ./main [options] file0.wav file1.wav ...
options:
-h, --help [default] show this help message and exit
-t N, --threads N [4 ] number of threads to use during computation
-p N, --processors N [1 ] number of processors to use during computation
-ot N, --offset-t N [0 ] time offset in milliseconds
-on N, --offset-n N [0 ] segment index offset
-d N, --duration N [0 ] duration of audio to process in milliseconds
-mc N, --max-context N [-1 ] maximum number of text context tokens to store
-ml N, --max-len N [0 ] maximum segment length in characters
-sow, --split-on-word [false ] split on word rather than on token
-bo N, --best-of N [2 ] number of best candidates to keep
-bs N, --beam-size N [-1 ] beam size for beam search
-wt N, --word-thold N [0.01 ] word timestamp probability threshold
-et N, --entropy-thold N [2.40 ] entropy threshold for decoder fail
-lpt N, --logprob-thold N [-1.00 ] log probability threshold for decoder fail
-debug, --debug-mode [false ] enable debug mode (eg. dump log_mel)
-tr, --translate [false ] translate from source language to english
-di, --diarize [false ] stereo audio diarization
-tdrz, --tinydiarize [false ] enable tinydiarize (requires a tdrz model)
-nf, --no-fallback [false ] do not use temperature fallback while decoding
-otxt, --output-txt [false ] output result in a text file
-ovtt, --output-vtt [false ] output result in a vtt file
-osrt, --output-srt [false ] output result in a srt file
-olrc, --output-lrc [false ] output result in a lrc file
-owts, --output-words [false ] output script for generating karaoke video
-fp, --font-path [/System/Library/Fonts/Supplemental/Courier New Bold.ttf] path to a monospace font for karaoke video
-ocsv, --output-csv [false ] output result in a CSV file
-oj, --output-json [false ] output result in a JSON file
-of FNAME, --output-file FNAME [ ] output file path (without file extension)
-ps, --print-special [false ] print special tokens
-pc, --print-colors [false ] print colors
-pp, --print-progress [false ] print progress
-nt, --no-timestamps [false ] do not print timestamps
-l LANG, --language LANG [en ] spoken language ('auto' for auto-detect)
-dl, --detect-language [false ] exit after automatically detecting language
--prompt PROMPT [ ] initial prompt
-m FNAME, --model FNAME [models/ggml-base.en.bin] model path
-f FNAME, --file FNAME [ ] input WAV file path
-oved D, --ov-e-device DNAME [CPU ] the OpenVINO device used for encode inference
-ls, --log-score [false ] log best decoder scores of tokens
例
# 输入audio_lesson_01_output.wav, 日语, ggml-large模型, srt文件输出
./main -osrt -m ./models/ggml-large.bin -f ~/audio_lesson_01_output.wav -l ja
效果
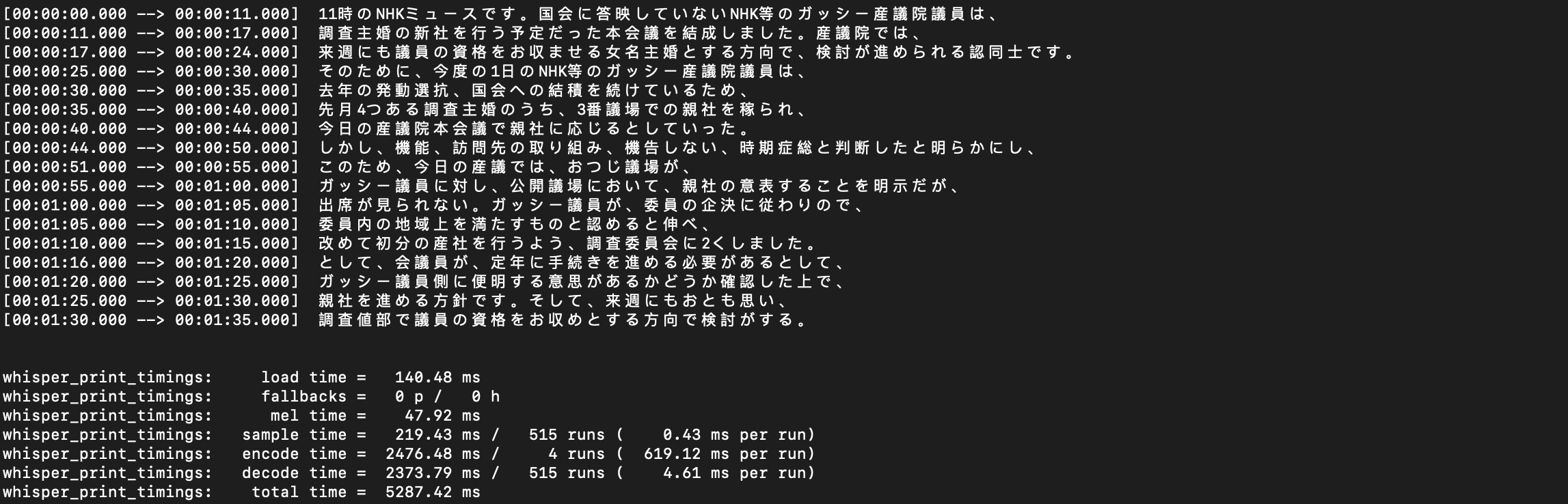
base model
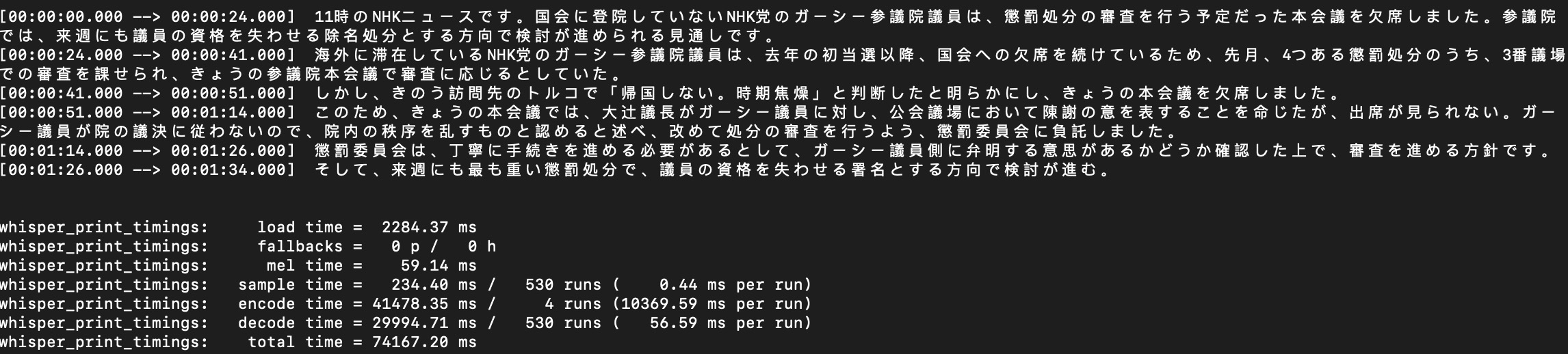
large model
[参考]